本文于 111 天前发布,最后更新于 91 天前
一、前言
本文可能不局限于 DM 数据库,用法是否可用需自行验证。
二、汇总
2.1 字段中是否包含中文
--查询NAME字段包含中文的 SELECT NAME FROM CS_ZW WHERE ASCIISTR(NAME) LIKE '%\%'; --查询NAME字段不包含中文的 SELECT NAME FROM CS_ZW WHERE ASCIISTR(NAME) NOT LIKE '%\%';
2.2 TIMESTAMP 类型取小时部分
SELECT DATE_FORMAT(SYSDATE(),'%H') AS HOUR FROM DUAL;
2.3 查询表的创建时间
SELECT NAME,CRTDATE AS "创建时间" FROM SYSOBJECTS WHERE "TYPE$" = 'SCHOBJ' AND "SUBTYPE$" = 'UTAB' AND NAME = '表名';
2.4 大字段类型查询时直接显示内容
创建测试表及数据
CREATE TABLE DZD (ID INT,B1 BLOB,C1 CLOB); INSERT INTO TEST.DZD VALUES (1,'ABCDEF','MAKDJIDIJFIJDIJIENG'); INSERT INTO TEST.DZD VALUES (2,'BCDEF','NGJDJIEJIJFIJEWNAAS'); INSERT INTO TEST.DZD VALUES (3,'CDEF','JMEIGNABEIJGIIANAI');
方法一:【BLOB 类型不适用】
SELECT ID,C1::VARCHAR FROM TEST.DZD;
方法二:
--DBMS_LOB.SUBSTR(BLOB/CLOB/TEXT) SELECT ID,DBMS_LOB.SUBSTR(B1),DBMS_LOB.SUBSTR(C1) FROM TEST.DZD;
方法三:
使用新工具 SQLark(百灵连接)
2.5 时间戳与日期类型的相互转化
日期类型转时间戳
SELECT UNIX_TIMESTAMP(SYSDATE);
时间戳转日期类型
SELECT FROM_UNIXTIME(1591644470); SELECT FROM_UNIXTIME(1591644470,'YYYY-MM-DD'); SELECT FROM_UNIXTIME(1591644470,'YYYY-MM-DD HH24:MI:SS');
另 - 13 位时间戳转化方法
--截取后直接转化 SELECT FROM_UNIXTIME(SUBSTR(1709187648234,0,10)) FROM DUAL; --TO_CHAR方式 SELECT TO_CHAR(1709187648234*1.0 / (1000*60*60*24) + TO_DATE('1970-01-01 08:00:00','YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD HH24:MI:SS'); SELECT TO_CHAR(1709187648234*1.0 / (1000*60*60*24) + TO_DATE('1970-01-01 08:00:00.000','YYYY-MM-DD HH24:MI:SS.MS'),'YYYY-MM-DD HH24:MI:SS.MS');
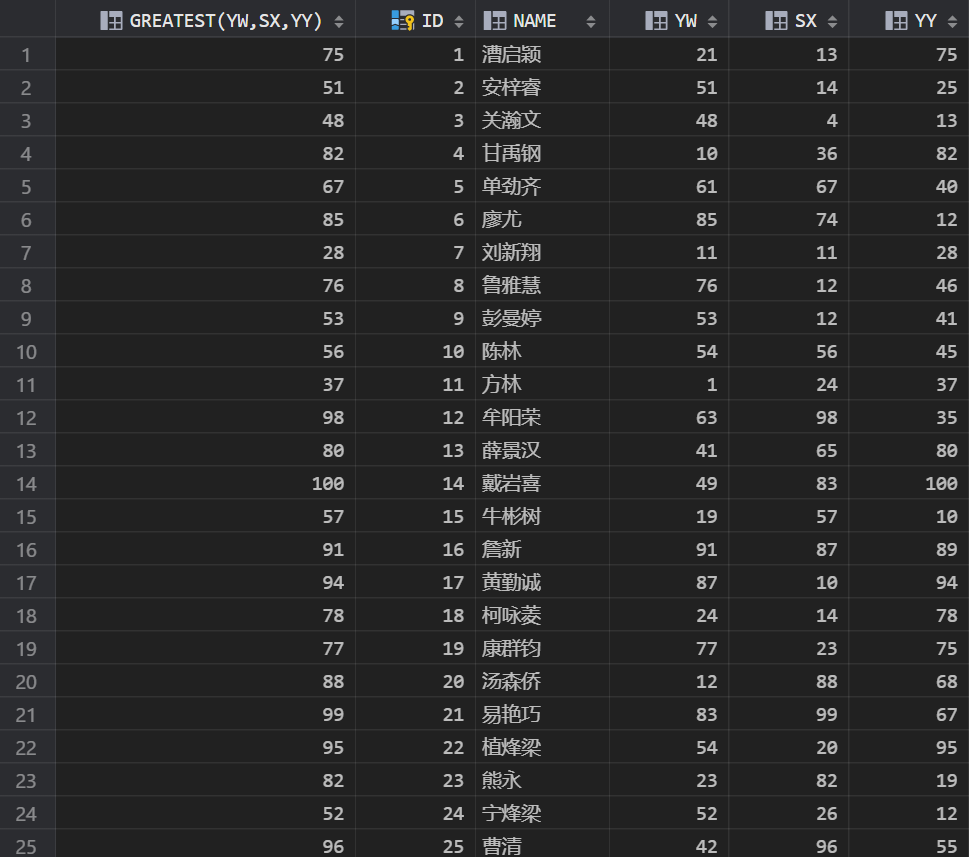
2.6 求一个或多个数中的最大值
创建测试表及数据
CREATE TABLE SCORE(ID INT PRIMARY KEY,NAME VARCHAR(30),YW INT,SX INT,YY INT);
使用 SQLark 的数据生成功能,生成成绩单数据。
--查询每名学生自己最好的一科成绩 SELECT GREATEST(YW,SX,YY),* FROM SCORE;
如图
2.7 计算一个字符串中某个字符的个数
示例:计算该字符串中 “F” 的个数。
SELECT LENGTH('ADSLFKJAKSJFDLJADSASF')-LENGTH(REPLACE('ADSLFKJAKSJFDLJADSASF', 'F' ,''));
思路:
思路:
- 将字符串中所找字符替换成”【就是将所找字符替换成空】
- 利用数学:字符串长度 - 字符串去掉所找字符后的长度 = 字符的个数
总结:
SELECT LENGTH('字符串')-LENGTH(REPLACE('字符串', '所找字符' ,''));
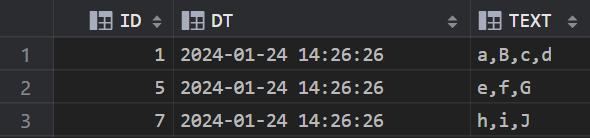
2.8 列转置(列转行)
创建测试表及数据
--创建表 CREATE TABLE LZH (ID INT, DT DATETIME (6), TEXT VARCHAR(8188)); --插入测试数据 INSERT INTO LZH (ID, DT, TEXT) VALUES (1, '2024-01-24 14:26:26.000000', 'a,B,c,d'); INSERT INTO LZH (ID, DT, TEXT) VALUES (5, '2024-01-24 14:26:26.000000', 'e,f,G'); INSERT INTO LZH (ID, DT, TEXT) VALUES (7, '2024-01-24 14:26:26.000000', 'h,i,J');
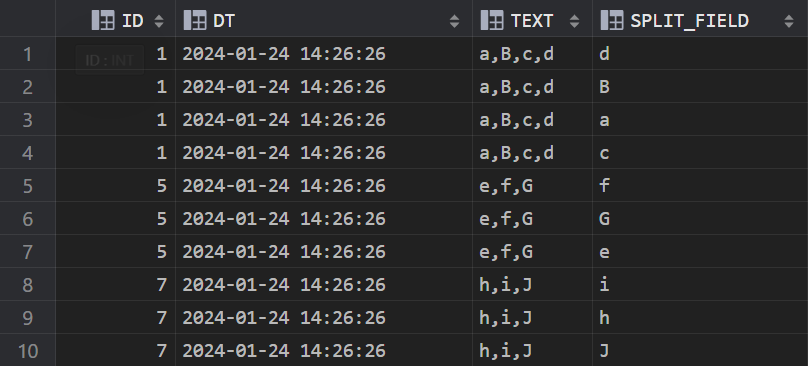
将 TEXT 字段以逗号分隔,拆分成新的一行数据
SELECT A.*, REGEXP_SUBSTR(A.TEXT, '[^,]{1,}', 1, B.L) AS SPLIT_FIELD FROM LZH A JOIN ( SELECT LEVEL AS L FROM DUAL CONNECT BY LEVEL <= 100 ) B ON REGEXP_COUNT (A.TEXT, ',') + 1 >= B.L ORDER BY 3;
效果:
2.9 虚拟列
表中某字段由其他字段计算所得 - 计算列
CREATE TABLE SCORE_TEST ( YW CHAR(10), SX CHAR(10), YY CHAR(10), ZF CHAR(10) AS (YW + SX + YY) ); INSERT INTO SCORE_TEST(YW,SX,YY) VALUES ('92','73','84'); SELECT * FROM SCORE_TEST;
如图:

2.10 二进制转化为相应的 ASCII 码文本
SELECT UTL_RAW.CAST_TO_VARCHAR2(DBMS_LOB.SUBSTR(BLOB字段)) FROM TABLENAME;
2.11 分区表将手机号以最后一位数字分十个子表
思路:使用虚拟列进行范围分区
CREATE TABLE PHONEINFO (NAME VARCHAR(20),PHONE VARCHAR(20),PHONE_TAIL_NUMBER CHAR(1) AS (SUBSTR(PHONE,-1))) PARTITION BY LIST(PHONE_TAIL_NUMBER) ( PARTITION P0 VALUES ('0'), PARTITION P1 VALUES ('1'), PARTITION P2 VALUES ('2'), PARTITION P3 VALUES ('3'), PARTITION P4 VALUES ('4'), PARTITION P5 VALUES ('5'), PARTITION P6 VALUES ('6'), PARTITION P7 VALUES ('7'), PARTITION P8 VALUES ('8'), PARTITION P9 VALUES ('9') );
2.12 CONCAT 函数拼接时间字段
CONCAT 函数拼接传参的字段时,时间字段不会带上单引号,可以在拼接字段时带上引号来解决
SELECT CONCAT('BETWEEN ',SYSDATE)--无单引号 UNION ALL SELECT CONCAT('BETWEEN ',''''||SYSDATE||'''');--加单引号
2.13 自定义函数实现字段拼接【CURSOR】
创建测试数据
CREATE TABLE ZIDUANPINJIE (ID INT NOT NULL PRIMARY KEY, NAME VARCHAR(30)); INSERT INTO ZIDUANPINJIE VALUES (1,'武汉'); INSERT INTO ZIDUANPINJIE VALUES (2,'达梦'); INSERT INTO ZIDUANPINJIE VALUES (3,'数据库'); INSERT INTO ZIDUANPINJIE VALUES (4,'股份'); INSERT INTO ZIDUANPINJIE VALUES (5,'有限'); INSERT INTO ZIDUANPINJIE VALUES (6,'公司'); INSERT INTO ZIDUANPINJIE VALUES (7,'成功'); INSERT INTO ZIDUANPINJIE VALUES (8,'上市'); INSERT INTO ZIDUANPINJIE VALUES (9,'科创板'); COMMIT;
函数定义
CREATE OR REPLACE FUNCTION PINJIE_ALL_DATA_FROM_TABLE RETURN VARCHAR IS V_RESULT VARCHAR(100); CURSOR TABLE_CURSOR IS SELECT * FROM ZIDUANPINJIE; BEGIN FOR REC IN TABLE_CURSOR LOOP V_RESULT := V_RESULT || REC.NAME; --V_RESULT := V_RESULT ||'||' || REC.NAME; -- 添加分隔符 END LOOP; RETURN V_RESULT; END; /
验证效果
SELECT "TEST"."PINJIE_ALL_DATA_FROM_TABLE"();
效果如图

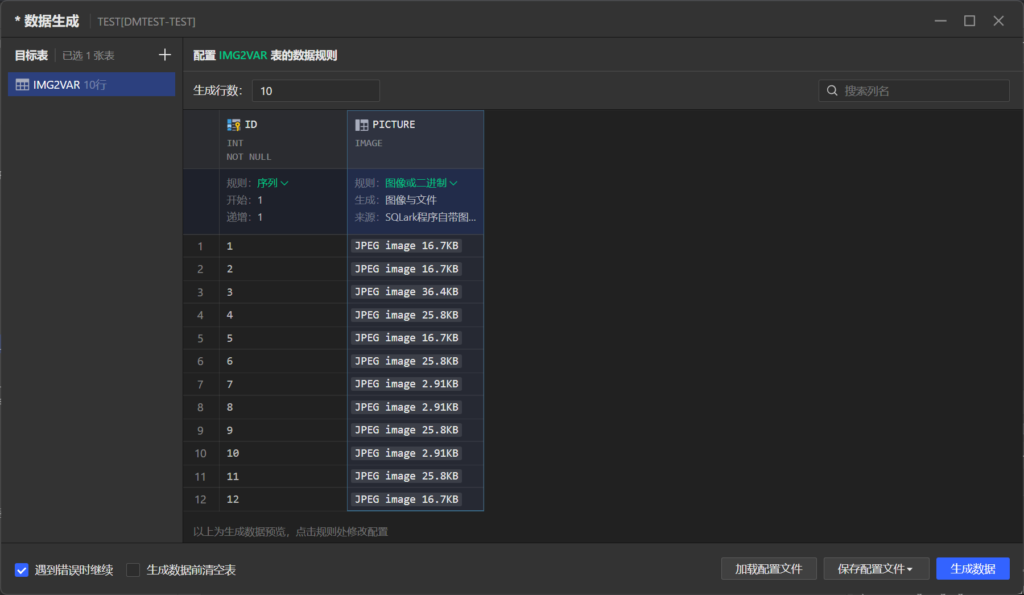
2.14 IMAGA 字段转换为 VARCHAR 字段
创建测试表
CREATE TABLE IMG2VAR (ID INT PRIMARY KEY, PICTURE IMAGE);
使用 SQLark 的数据生成功能生成测试数据
转换
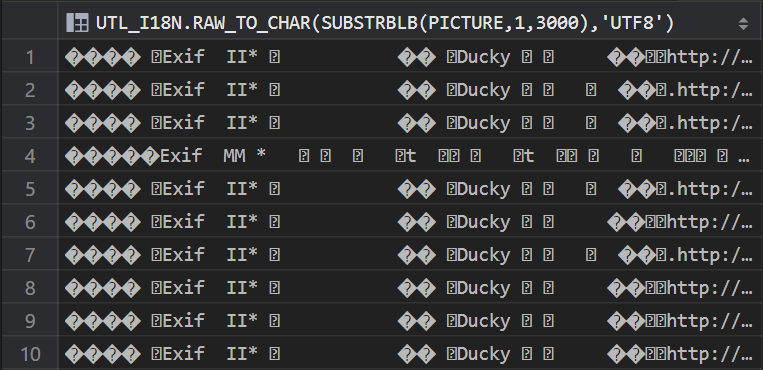
SELECT UTL_I18N.RAW_TO_CHAR(SUBSTRBLB(PICTURE,1,3000),'UTF8') FROM TEST.IMG2VAR;
效果图
2.15 LIKE 转义 ESCAPE
创建测试数据
CREATE TABLE TEST_LIKE (ID INT, NAME VARCHAR(200)); INSERT INTO TEST_LIKE VALUES(1,'FFFF'); INSERT INTO TEST_LIKE VALUES(2,'FF_FF'); INSERT INTO TEST_LIKE VALUES(3,'FF\FF'); INSERT INTO TEST_LIKE VALUES(4,'FF_A\A'); INSERT INTO TEST_LIKE VALUES(5,'FF_\FF'); INSERT INTO TEST_LIKE VALUES(6,'FF\_FF'); INSERT INTO TEST_LIKE VALUES(7,'FF%_%FF'); COMMIT;
一些查询示例:
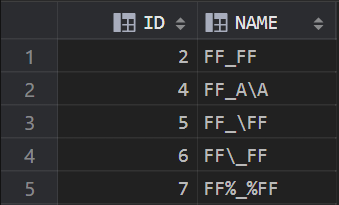
(1)查询包含 “_” 的数据
SELECT * FROM TEST_LIKE WHERE NAME LIKE '%\_%' ESCAPE '\'; --或者 SELECT * FROM TEST_LIKE WHERE NAME LIKE '%A_%' ESCAPE 'A';
效果图:
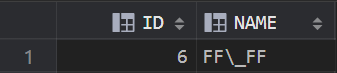
(2)查询包含 “\_” 的数据
SELECT * FROM TEST_LIKE WHERE NAME LIKE '%\\\_%' ESCAPE '\';
效果图:
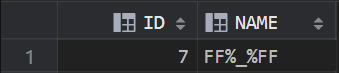
(3)查询包含 “%” 的数据
SELECT * FROM TEST_LIKE WHERE REGEXP_LIKE (NAME,'%'); --或者 SELECT * FROM TEST_LIKE WHERE NAME LIKE '%\%%' ESCAPE '\';
效果图:
2.16 字符串按分割符拆分成一列的多行
示例:将字符串 “AAA|BBB|CCC|DDD|EEE”,按 “|” 截取
方法一:SUBSTRING_INDEX 嵌套
SELECT SUBSTRING_INDEX('AAA|BBB|CCC|DDD|EEE','|',1) UNION ALL --AAA SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('AAA|BBB|CCC|DDD|EEE','|', 2),'|',-1) UNION ALL --BBB SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('AAA|BBB|CCC|DDD|EEE','|', 3),'|',-1) UNION ALL --CCC SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('AAA|BBB|CCC|DDD|EEE','|', 4),'|',-1) UNION ALL --DDD SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('AAA|BBB|CCC|DDD|EEE','|', 5),'|',-1); --EEE
方法二:REGEXP_SUBSTR 结合 LEVEL
SELECT REGEXP_SUBSTR('AAA|BBB|CCC|DDD|EEE', '[^|]+', 1, LEVEL) AS SPLIT_VALUE FROM DUAL CONNECT BY REGEXP_SUBSTR('AAA|BBB|CCC|DDD|EEE', '[^|]+', 1, LEVEL) IS NOT NULL;
方法三:
DECLARE V_COUNT INT; V_DATA VARCHAR(50); V_SQL VARCHAR(5000); BEGIN SELECT LENGTH('AAA|BBB|CCC|DDD|EEE') - LENGTH(REPLACE('AAA|BBB|CCC|DDD|EEE', '|', '')) + 1 INTO V_COUNT FROM DUAL; EXECUTE IMMEDIATE 'DROP TABLE IF EXISTS RESULT_TABLE;'; EXECUTE IMMEDIATE 'CREATE TABLE RESULT_TABLE (RES VARCHAR2(50));'; FOR I IN 1 .. V_COUNT LOOP SET V_DATA = SUBSTRING_INDEX(SUBSTRING_INDEX('AAA|BBB|CCC|DDD|EEE', '|', I), '|', -1); V_SQL = 'INSERT INTO RESULT_TABLE VALUES (:1);'; EXECUTE IMMEDIATE V_SQL USING V_DATA; END LOOP; END;
查询验证
SELECT * FROM RESULT_TABLE;
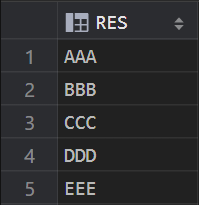
总结模板:
DECLARE V_COUNT INT; V_DATA VARCHAR(50); V_SQL VARCHAR(5000); BEGIN SELECT LENGTH('字符串')-LENGTH(REPLACE('字符串', '分割符' ,''))+1 INTO V_COUNT FROM DUAL; EXECUTE IMMEDIATE 'DROP TABLE IF EXISTS RESULT_TABLE;'; EXECUTE IMMEDIATE 'CREATE TABLE RESULT_TABLE (RES VARCHAR2(50));'; FOR I IN 1..V_COUNT LOOP SET V_DATA = SUBSTRING_INDEX(SUBSTRING_INDEX('字符串','分割符', I),'分割符',-1); V_SQL = 'INSERT INTO RESULT_TABLE VALUES (:1);'; EXECUTE IMMEDIATE V_SQL USING V_DATA; END LOOP; END; --查询结果 SELECT * FROM RESULT_TABLE;
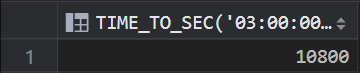
2.17 时间转化成秒数
SELECT TIME_TO_SEC('03:00:00') from dual;
效果:
三、后续
该文档不定时更新,如有发现新的 SQL,随时同步到该文章。

