一、前言
本文可能不局限于DM数据库,用法是否可用需自行验证。
二、汇总
2.1 字段中是否包含中文
--查询NAME字段包含中文的
SELECT NAME FROM CS_ZW WHERE ASCIISTR(NAME) LIKE '%\%';
--查询NAME字段不包含中文的
SELECT NAME FROM CS_ZW WHERE ASCIISTR(NAME) NOT LIKE '%\%';2.2 TIMESTAMP类型取小时部分
SELECT DATE_FORMAT(SYSDATE(),'%H') AS HOUR FROM DUAL;2.3 查询表的创建时间
SELECT NAME,CRTDATE AS "创建时间" FROM SYSOBJECTS WHERE "TYPE$" = 'SCHOBJ' AND "SUBTYPE$" = 'UTAB' AND NAME = '表名';2.4 大字段类型查询时直接显示内容
创建测试表及数据
CREATE TABLE DZD (ID INT,B1 BLOB,C1 CLOB);
INSERT INTO TEST.DZD VALUES (1,'ABCDEF','MAKDJIDIJFIJDIJIENG');
INSERT INTO TEST.DZD VALUES (2,'BCDEF','NGJDJIEJIJFIJEWNAAS');
INSERT INTO TEST.DZD VALUES (3,'CDEF','JMEIGNABEIJGIIANAI');方法一:【BLOB类型不适用】
SELECT ID,C1::VARCHAR FROM TEST.DZD;方法二:
--DBMS_LOB.SUBSTR(BLOB/CLOB/TEXT)
SELECT ID,DBMS_LOB.SUBSTR(B1),DBMS_LOB.SUBSTR(C1) FROM TEST.DZD;方法三:
使用新工具SQLark(百灵连接)
2.5 时间戳与日期类型的相互转化
日期类型转时间戳
SELECT UNIX_TIMESTAMP(SYSDATE);时间戳转日期类型
SELECT FROM_UNIXTIME(1591644470);
SELECT FROM_UNIXTIME(1591644470,'YYYY-MM-DD');
SELECT FROM_UNIXTIME(1591644470,'YYYY-MM-DD HH24:MI:SS');另-13位时间戳转化方法
--截取后直接转化
SELECT FROM_UNIXTIME(SUBSTR(1709187648234,0,10)) FROM DUAL;
--TO_CHAR方式
SELECT TO_CHAR(1709187648234*1.0 / (1000*60*60*24) + TO_DATE('1970-01-01 08:00:00','YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD HH24:MI:SS');
SELECT TO_CHAR(1709187648234*1.0 / (1000*60*60*24) + TO_DATE('1970-01-01 08:00:00.000','YYYY-MM-DD HH24:MI:SS.MS'),'YYYY-MM-DD HH24:MI:SS.MS');2.6 求一个或多个数中的最大值
创建测试表及数据
CREATE TABLE SCORE(ID INT PRIMARY KEY,NAME VARCHAR(30),YW INT,SX INT,YY INT);使用SQLark的数据生成功能,生成成绩单数据。
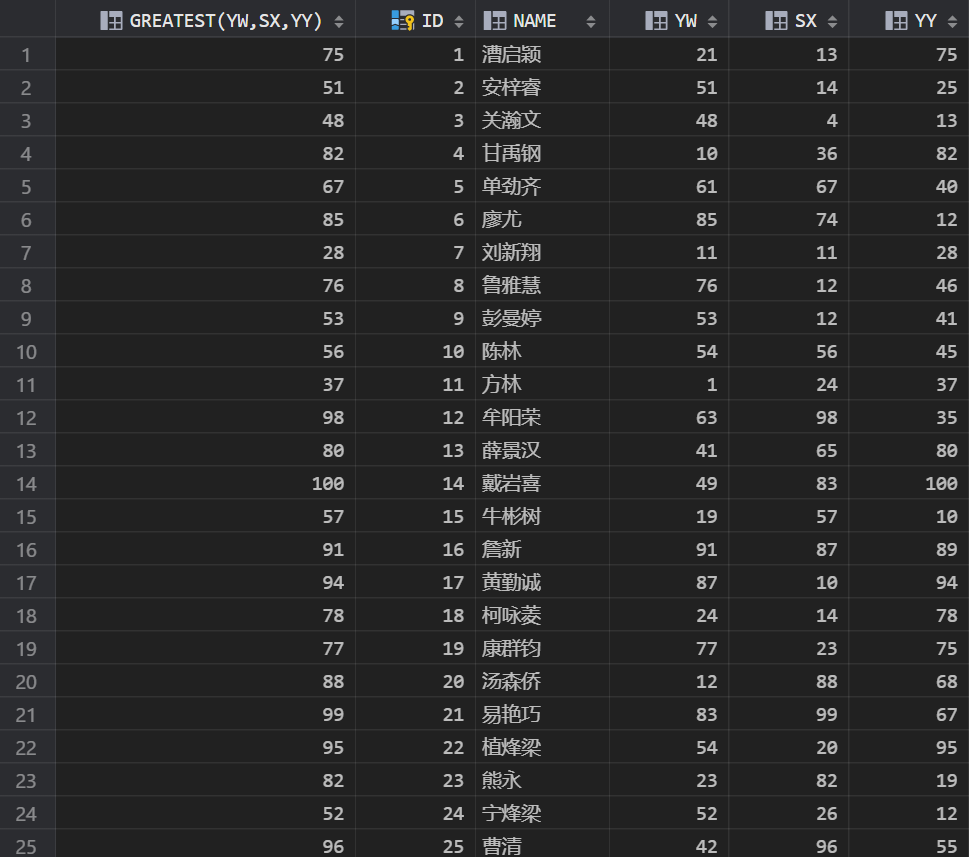
--查询每名学生自己最好的一科成绩
SELECT GREATEST(YW,SX,YY),* FROM SCORE;如图
2.7 计算一个字符串中某个字符的个数
示例:计算该字符串中“F”的个数。
SELECT LENGTH('ADSLFKJAKSJFDLJADSASF')-LENGTH(REPLACE('ADSLFKJAKSJFDLJADSASF', 'F' ,''));思路:
思路:
- 将字符串中所找字符替换成”【就是将所找字符替换成空】
- 利用数学:字符串长度-字符串去掉所找字符后的长度=字符的个数
总结:
SELECT LENGTH('字符串')-LENGTH(REPLACE('字符串', '所找字符' ,''));2.8 列转置(列转行)
创建测试表及数据
--创建表
CREATE TABLE LZH (ID INT, DT DATETIME (6), TEXT VARCHAR(8188));
--插入测试数据
INSERT INTO LZH (ID, DT, TEXT) VALUES (1, '2024-01-24 14:26:26.000000', 'a,B,c,d');
INSERT INTO LZH (ID, DT, TEXT) VALUES (5, '2024-01-24 14:26:26.000000', 'e,f,G');
INSERT INTO LZH (ID, DT, TEXT) VALUES (7, '2024-01-24 14:26:26.000000', 'h,i,J');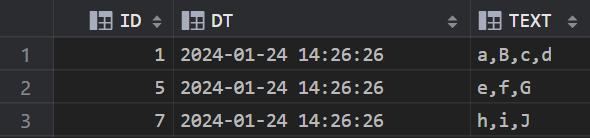
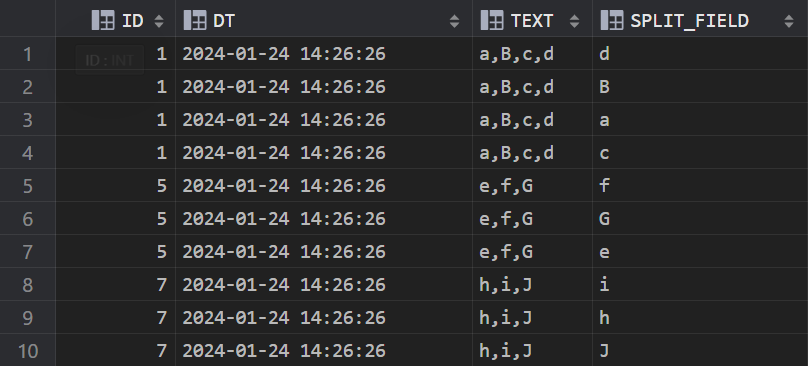
将TEXT字段以逗号分隔,拆分成新的一行数据
SELECT
A.*,
REGEXP_SUBSTR(A.TEXT, '[^,]{1,}', 1, B.L) AS SPLIT_FIELD
FROM
LZH A
JOIN (
SELECT
LEVEL AS L
FROM
DUAL
CONNECT BY LEVEL <= 100
) B ON REGEXP_COUNT (A.TEXT, ',') + 1 >= B.L
ORDER BY
3;效果:
2.9 虚拟列
表中某字段由其他字段计算所得-计算列
CREATE TABLE SCORE_TEST (
YW CHAR(10),
SX CHAR(10),
YY CHAR(10),
ZF CHAR(10) AS (YW + SX + YY)
);
INSERT INTO SCORE_TEST(YW,SX,YY) VALUES ('92','73','84');
SELECT * FROM SCORE_TEST;如图:

2.10 二进制转化为相应的ASCII码文本
SELECT UTL_RAW.CAST_TO_VARCHAR2(DBMS_LOB.SUBSTR(BLOB字段)) FROM TABLENAME;三、后续
该文档不定时更新,如有发现新的SQL,随时同步到该文章。
